Et ca permet aussi de récupérer des backlinks via du bad buzz : La Voix du Nord
Bref, ca donne une image très moyenne de la marque en plus davoir un effet négatif sur le SEO en multipliant les pages que Google pourrait assimiler à du spam.
Une fois ce constat posé, nous allons voir une méthode qui permet de détecter les cas où un site na pas de produits pertinents pour une requête.
Pour se faire, nous allons utiliser R et un outil de reconnaissance dimages type Google Vision
Etape 1 : Récupérer des mots-clés dans votre thématique
Je ne vais pas vous apprendre grand chose sur cette étape. Utilisez vos outils préférés (Keyword Planner, SEMrush, Ubersuggest, Seoquantum, etc).
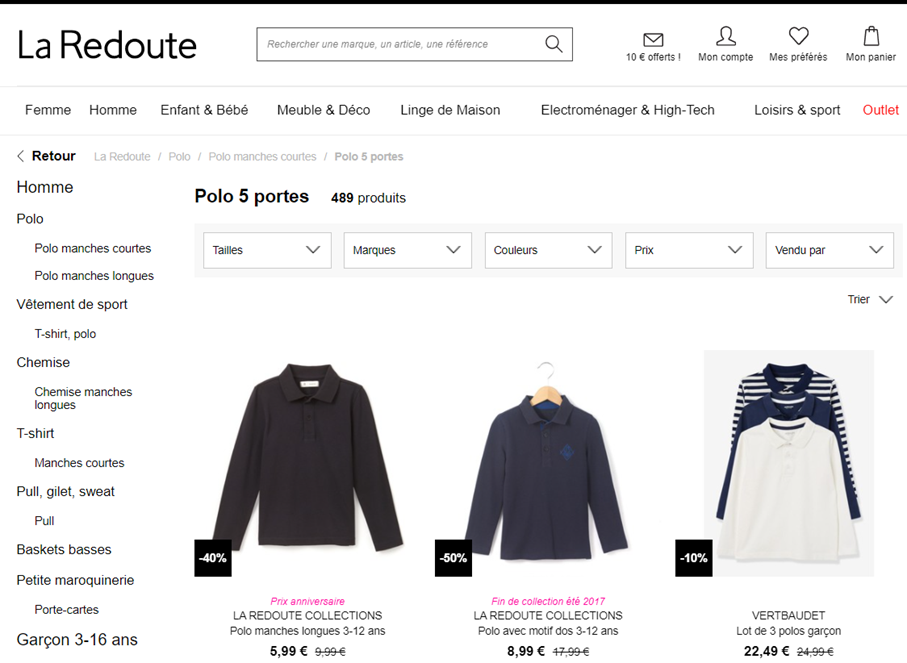
Pour lexemple, je vais prendre une recherche sur des vêtements « Polo homme ».
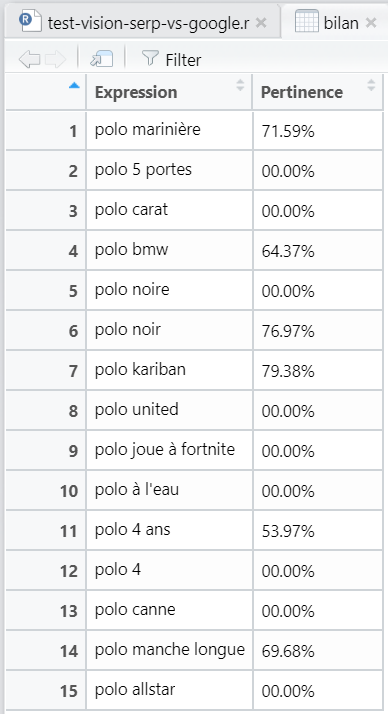
Et on va partir sur 15 expressions à tester sur le site de La Redoute :
- polo marinière
- polo 5 portes
- polo carat
- polo bmw
- polo noire
- polo noir
- polo kariban
- polo united
- polo joue à fortnite
- polo à leau
- polo 4 ans
- polo 4
- polo canne
- polo manche longue
- polo allstar
Même manuellement, ça ne paraît pas toujours évident de statuer sur la pertinence de chaque expression.
Etape 2 : Récupérer les URLs des images
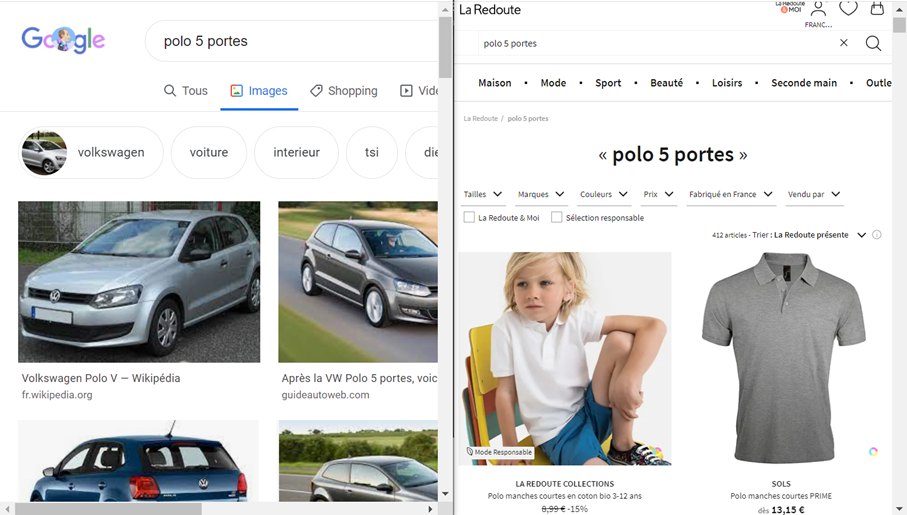
Pour faire travailler loutil de reconnaissance visuelle, il faut récupérer les URLs des premières images de Google Images pour chaque requête.
Plusieurs possibilités :
- Soit, vous demandez à un prestataire (Ranks, Monitorank, Myposeo, etc) de vous fournir les URLs des images qui saffichent sur vos mots-clés.
- Soit, vous utilisez un service comme DataForSEO pour vous retourner les URLs des images via une API.
- Soit, vous créez un script pour scraper Google Images (bon courage)
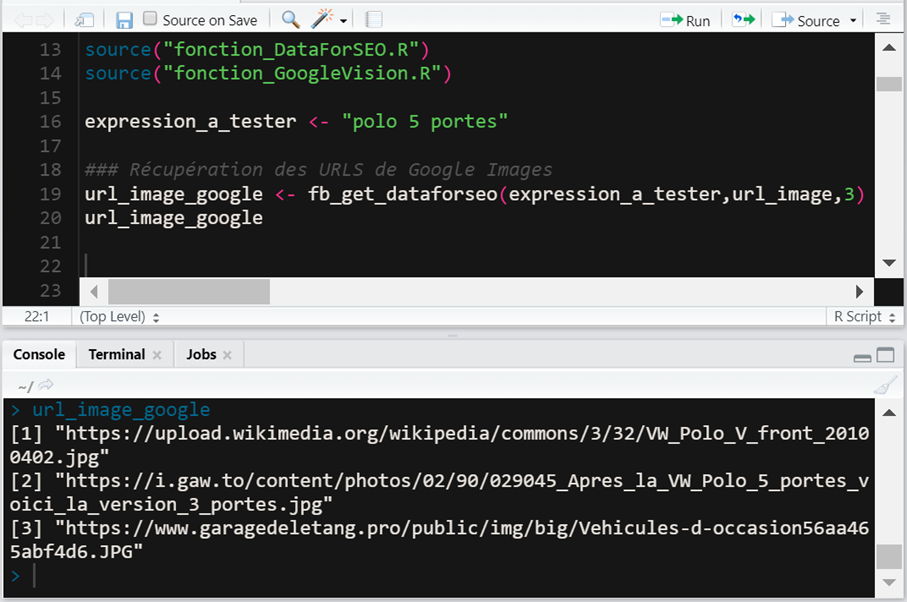
L'objectif étant de récupérer dans R les URLs des images pour vos expressions :
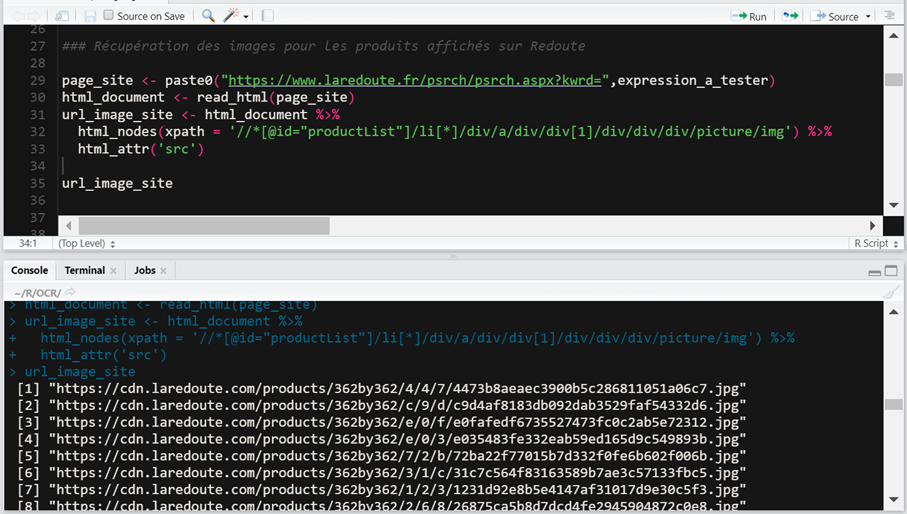
Il faut ensuite récupérer les URLs des images qui safficheraient pour la même requête sur votre site. Souvent, lancer lexpression dans le moteur interne permet de facilement récupérer les images des produits.
Cest assez simple de récupérer les URLs avec quelques lignes de R.
Et voilà, nous avons les URLs des images provenant de Google Images et celles du site La Redoute.
Etape 3 : Passer les URLs dans Google Vision pour récupérer des tags
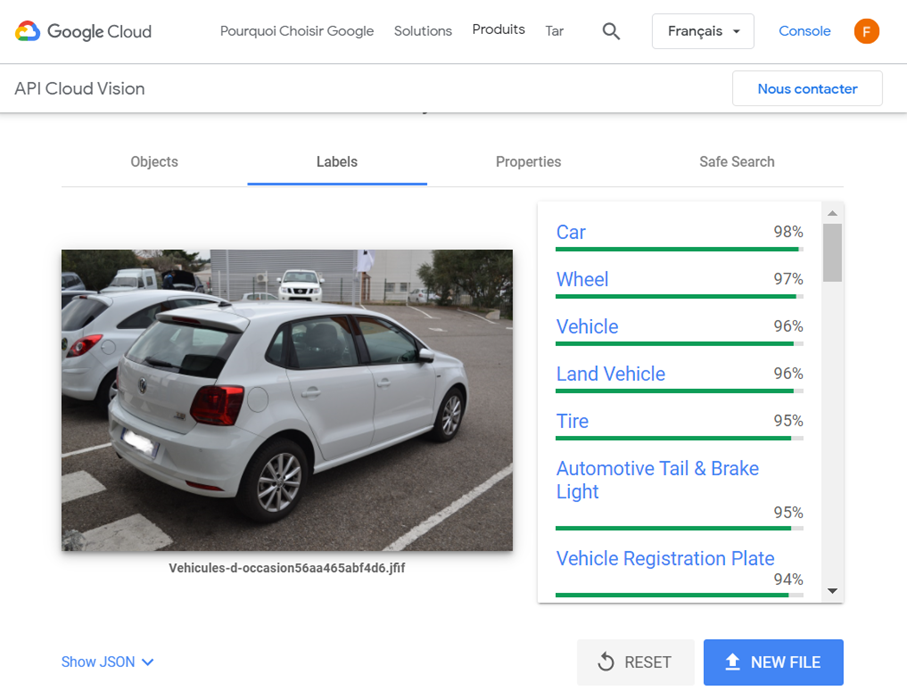
On passe un nombre défini dURLs provenant de Google Images dans Google Vision. Ici, jai paramétré 3 images à tester, on peut en faire davantage ce qui rendra les résultats plus fiables, mais ça coûtera aussi plus cher chez Google Vision.
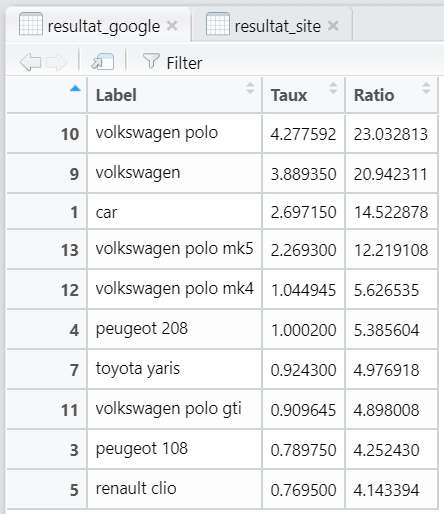
Pour chaque URL, Google vision va retourner des tags avec un pourcentage de confiance :
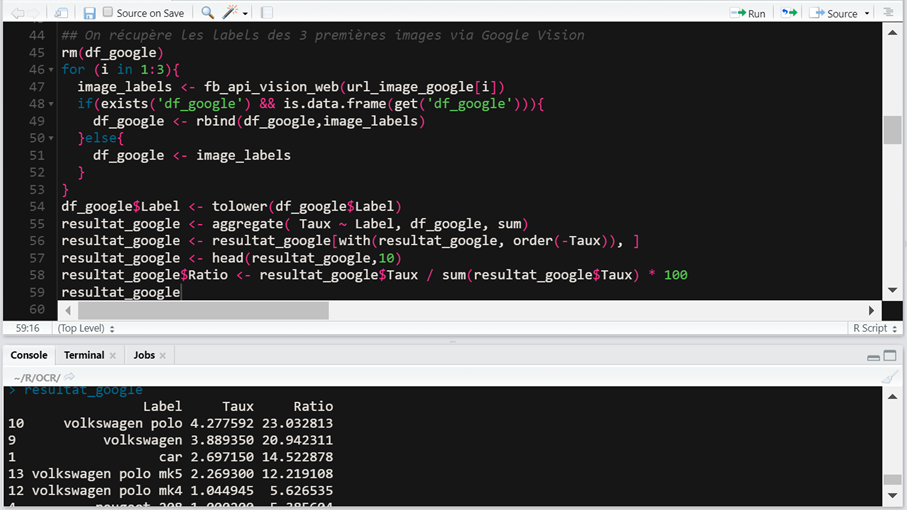
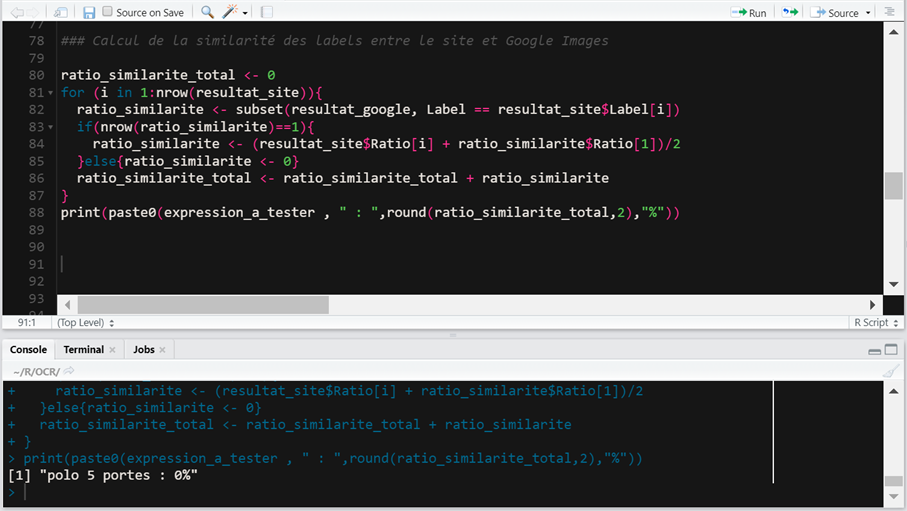
Via R, on appelle lAPI de Google Vision pour les 3 URLs, et on fait un rapide calcul pour additionner les tags qui reviennent le plus souvent avec le plus haut taux de confiance. Et on met un ratio en base 100.
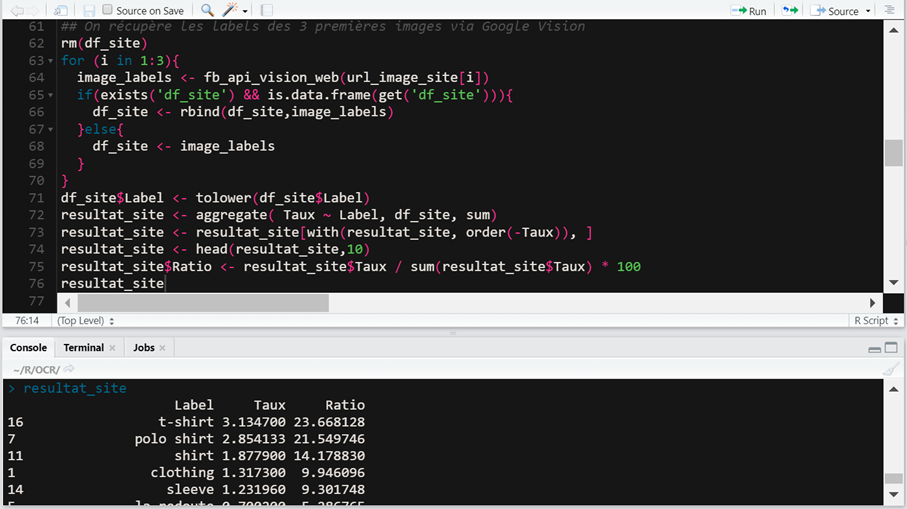
On fait exactement la même chose pour les 3 premières URLs images provenant du site La Redoute :
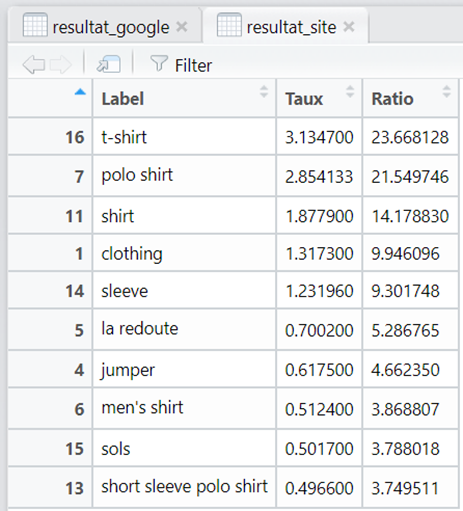
Et voilà, le plus difficile est fait, nous avons 2 sets de tags quil ny a plus quà comparer.