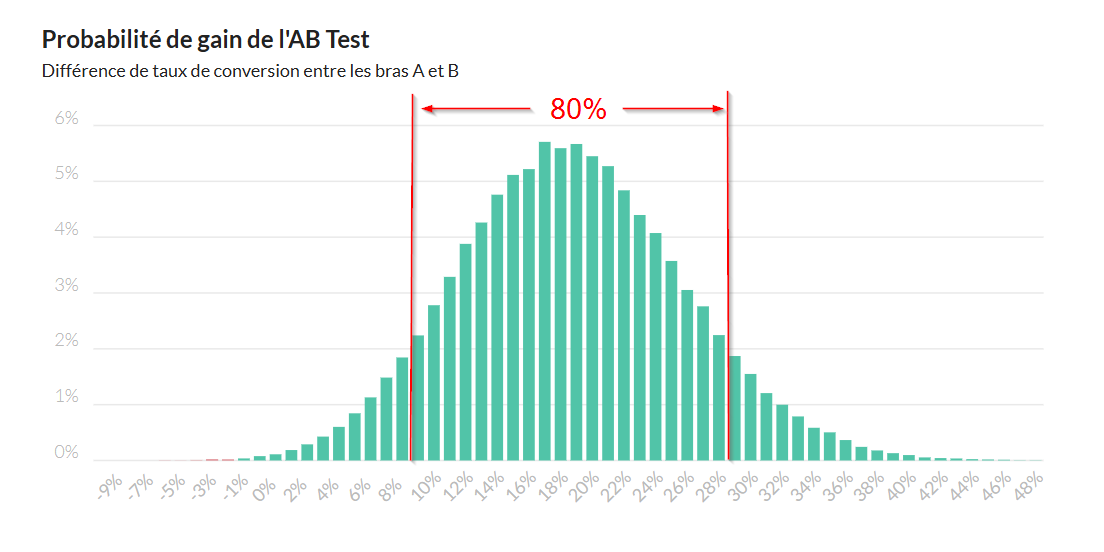
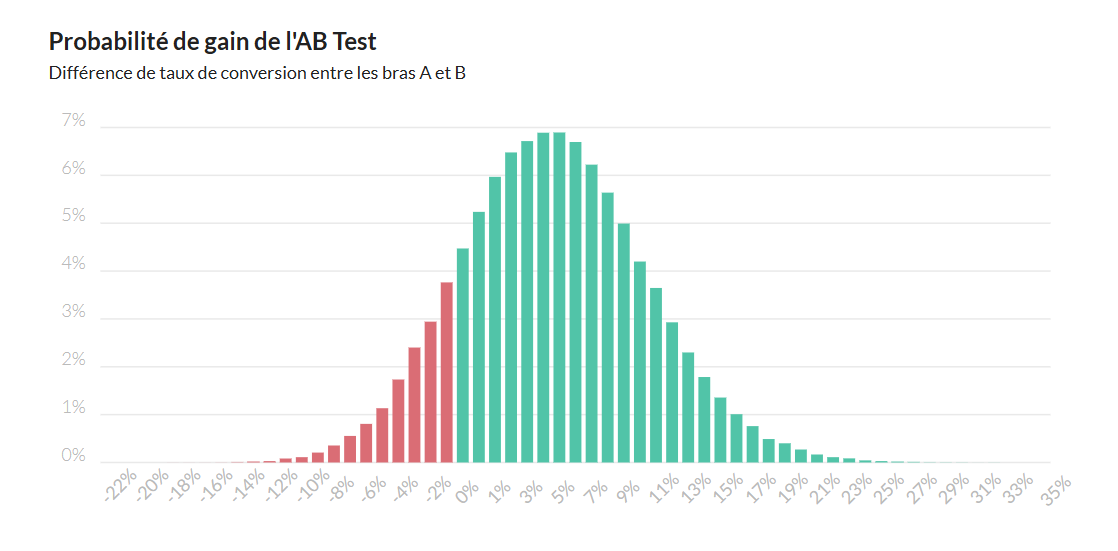
La plupart des régies et des agences arrêtent leur analyse de fiabilité des A/B tests juste sur l'intervalle de confiance statistique.
Cependant, l'intervalle de confiance part toujours du postulat que les 2 bras de l'A/B test sont 100% équivalents pour lancer l'analyse, ce qui en réalité n'est jamais exact voire parfois complètement faux.
On utilise le plus souvent 3 méthodes pour spliter une campagne en 2 bras "presque" équivalents. Mais toutes ont des biais.
La méthode User Based
Cette méthode prend juste aléatoirement des internautes pour les répartir dans le bras A ou dans le bras B.
Cependant, si on a le même volume dinternautes dans chaque bras, on ne contrôle rien de leur qualité.
On peut facilement avoir une proportion des meilleurs clients fidèles plus grande dans lun des bras vs lautre.
Par nature, les 2 bras ne seront jamais 100% équivalent. Dès le début, il y aura un biais de quelques pourcents qui correspondent à des internautes plus ou moins appétents à la marque dans les bras.
La méthode Géographique
On estime quune zone géographique a très exactement les mêmes performances quune autre zone en se basant sur les données historiques.
Déjà, il faut comprendre que les données passées ne préjugent pas à 100% des données futures.
De très petits paramètres, comme la météo, les congés, des grands événements sportifs, le mois de lannée peuvent modifier fortement la performance par géographie.
Par exemple, 20% des Parisiens vont au ski chaque année. Si vous avez Paris ou la région Rhône-Alpes dans un test en février/mars, vous allez avoir un biais dès le départ, car vous allez cibler temporairement un volume conséquent d'internautes qui était ailleurs lors du calcul des bras.
La méthode aux produits
Cest le protocole FeedX chez Google, on découpe un groupe de produits en 2 groupes différents avec presque le même historique de performance.
Sûrement la méthode qui peut le plus vite générer des biais dans les bras d'A/B Test.
Il suffit que quelques top produits changent de prix, ou passent hors stock, ou la saisonnalité qui change, ou des nouveaux produits très performants qui cannibalisent ceux du test.
Bref, il suffit de peu de chose pour que les bras n'aient plus du tout la même performance.
Et en plus, c'est très difficile d'estimer quand les bras sont non équivalents car on attribuera toujours les écarts aux éléments variants dans le test.
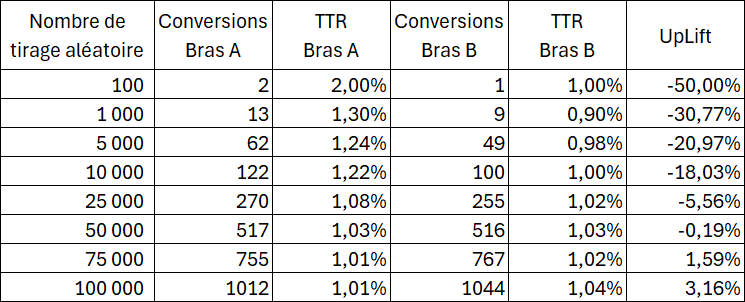
Pour ajouter encore du biais, les algorithmes de pilotage ne gardent pas une pression constante sur les 2 bras lorsqu'on pilote au CPA ou au ROAS.
Google ne peut pas attendre 1000 conversions sur une campagne pour avoir des certitudes statistiques sur les performances.
Dès les premières conversions, les budgets entre les bras se déphasent facilement et on récupère vite une diffusion différente.
On voit souvent des tests, où on doit intervenir pour freiner ou accélérer la diffusion dun bras pour ré-équilibrer le volume investi.
Bien entendu, ce n'est pas neutre sur la fiabilité du test, si un bras a fait plus de volume sur une période, on ne peut pas compenser en baissant le volume sur la période suivante sans biaiser les données.
Quand vous faites un test, vous devez additionner les 3 types de biais ci-dessus.
Autant dire que ça devient très compliqué de détecter avec certitude des gains avec une marge d'erreur de moins de 5%. Et pourtant, c'est cet ordre de grandeur que génère la quasi-totalité des A/B tests que je vois.
Il faut se rendre à l'évidence, dans beaucoup de cas, si vous voyez des lifts à +50% soit vous partez de très loin soit votre test est biaisé :)
Il faudrait être assez lucide pour s'en rendre compte, même si, pouvoir communiquer des bons chiffres est toujours tentant 👀
Rendez-vous sur Twitter Linkedin pour me donner votre avis. >>cliquez-ici<<



{kind=link}
{kind=link}